開発工程との統合
このページは、案件責任者や技術責任者が、Nijoを採用するかどうかを判断するための観点を整理したものです。 開発者向けの操作説明ではなく、見積り、体制、変更管理、保守運用の観点から、Nijoをプロジェクトにどう組み込むかを説明します。
採用判断
Nijoは、業務アプリケーションのうち、データ構造とその周辺の処理をモデルとして定義し、そこからソースコードを自動生成するためのフレームワークです。 したがって、採用判断では「開発作業が丸ごと自動化されるか」ではなく、以下を分けて考える必要があります。
- 省力化しやすい領域(自動生成される部分) : データ構造定義、定型的なCRUD、一覧検索、型定義の同期、基本的なバリデーション
- 引き続き案件側で設計責任を持つ領域(手動実装が必要な部分) : UI、個別の業務ロジック、外部システム連携、運用設計
この切り分けを受け入れられる案件ほど、Nijoとの相性が良くなります。
向いている案件
以下のような案件では、Nijoを採用する価値を説明しやすくなります。
- データ構造の変更や追加が多く、フロントエンド・バックエンド・データベースの整合性維持が負担になりやすい
- 一覧検索、登録更新、参照といった定型処理が多い
- 開発メンバーの増減が多く発生する。新規参画メンバーに設計の全体像を共有し続けたいというニーズが高い
- 型安全性を重視し、フロントエンド、バックエンド、データベースの不整合を減らしたい
- 業務データの完全性(排他制御や同時更新などによりデータが壊れないこと)が重要である
- 変更容易性が重要である。管理対象項目の増減や変更が頻繁に発生する、あるいは将来的に発生する可能性が高いと見込まれる
- 初期の学習コストよりも、中長期の変更容易性を重視する
慎重に判断すべき案件
以下のような案件では、導入効果よりも別の負担が目立つ可能性があります。
- 画面表現やUXの独自性が主な競争力であり、データ処理の定型部分が少ない
- 既存システムの資産や既存設計書を強く前提としており、モデル中心の整理に切り替えにくい
- 複数の開発会社で同じコードベースを共有しており、かつ他の会社にNijoを使ってくれと指示できないなど、開発チームがスキーマ定義を中心に設計を進める運用に乗れない
- 短期間の小規模改修で、導入学習コストを回収しづらい
ただし、小規模案件やPoCでも、将来的な本開発を見据えてモデリング方針を先に固めたい場合には、採用意義があります。 PoCで使う場合は、最初から全面採用を目指すよりも、データ構造の整理と主要な定型処理の自動生成に絞って評価するほうが現実的です。
V字モデルから見たNijoの役割
一般的なV字モデルの工程ごとに、Nijoが何を担うか、逆にどの作業は従来のスクラッチ開発と同様かの概要を記載します。 Nijoは、従来の工程をなくすというより、工程ごとの作業内容と重心を変えます。
外部工程 (要求整理 〜 要件定義 〜 外部設計・基本設計)
以下の理由から、基本的に外部工程での Nijo の活用は射程範囲外です。
- 外部工程ではPoC、モックアップといった「動かなくてもよいからとにかくイメージを形にする」ことが重視されるところ、 Nijo が生成するコードは実運用を想定したものであるため、例えば未実装部分がある場合は厳密にエラーになる
- UI自体は自動生成されない
ただし、以下の使い方をすることで部分的に外部工程に役立てることは可能です。
- スキーマ定義用のGUIエディタを依頼者や開発者間の認識合わせの道具として利用する
- 実際にデータ構造や画面項目を定義し、設計の矛盾点が無いかを確かめる
- Nijoのコード自動生成処理と組み合わせたモックUIの動的作成処理を予め作り込んでおき、スキーマ定義を変更したらUIにも反映されるようにしておく
内部工程 (内部設計 〜 実装)
Nijo の恩恵を最も受けられるのが内部工程です。データ構造の定義や定型処理の自動生成により、設計と実装の効率が大幅に向上します。 手動実装が必要な部分も残るので、何が自動生成されるかを理解するのが重要です。
- 自動生成
- データ構造定義。特にWebクライアント側とWebサーバー側の同期
- 一覧検索処理(フィルタリング、ページング、ソート)
- 必須入力、桁数制限など、単項目のエラーチェック。個別の機能への実装が不要で、スキーマ定義で項目ごとに定義すれば終わる
- 楽観排他制御が既定で入るため実装漏れが減る
- 項目単位のエラーメッセージのサーバー側からクライアント側への運搬
- 手動実装
- UIのレイアウトや操作フロー
- 個別の業務ロジック(例: 仕入単価が変更されたら過去の発注データも更新する、月次締めが済んだら更新不可、などなど)
- 外部システム連携
- トランザクションの範囲の設計
- 運用設計(例: ログの出力方針、マイグレーション手順、障害時の復旧手順)
このドキュメント内の他のページで詳細に説明しています。 またデモ101にて実用的な例を示しているのであわせて参照してください。
なお、 ソースコードの自動生成は一度かけて終わりではなく、開発期間を通じて継続的に行われます。 どのように手動実装部分と統合しているかは アーキテクチャ概要 を参照してください。
重要な点は、 スキーマ定義も実装の一部 としてそれなりのウェイトを占めるため、誰がスキーマ定義を行うか、誰がそのレビューを行うかを早い段階で決めておく必要があります。 ここが曖昧なままだと、生成コードに何を期待してよいかがメンバーごとにずれやすく、導入効果が下がります。
役割分担の一例:
- 案件責任者: Nijoで省力化する範囲と、案件側で個別設計する範囲を決める
- 技術責任者: モデル設計方針、生成コードの扱い、カスタマイズ方針を決める
- 開発者:
nijo.xmlの更新、生成コードの利用、個別実装を行う - レビュー担当者: モデル定義、生成コード利用方法、手実装ロジックの境界を確認する
テスト工程 (単体・結合・総合・受入テスト)
テスト対象については、自動生成された部分を毎回ゼロからテストする対象として扱うのではなく、既知の生成規則に基づく部分として扱いやすくなります。多くの場合、 不具合が出るのは手動実装の部分 に集中してくるので、そこにテスト資源を集中させることが重要になります。最終的にどこまでテストするかの判断は案件ごとの品質方針で決めてください。
また、 テスト計画の立案や、テスターと設計者の間の仕様認識合わせの効率化 も期待できます。 スキーマ定義では機能間の関連性が明示されるため、どの機能を動かすとどのデータが更新され後続のどの画面に影響するのかといった関係性を把握しやすくなります。
保守運用
少なくない現場で、開発者と運用担当者は別の人間・別のチームになります。 この場合、運用担当者がシステムの構造を理解し、障害対応や変更対応を行うための情報共有が重要になります。 Nijoのスキーマ定義は、通常のドキュメントと異なり実装と同期されている保証があるため、運用担当者はこれを信用してシステムの理解を始めることでその全体像を把握しやすくなります。
また、SaaS型のノーコードツールと異なりシステムの詳細は全てソースコードとして出力される(ブラックボックス部分が無い)ため、運用担当者がコードを直接確認して障害調査を行うことができます。
品質保証の考え方
Nijoの採用により、品質保証の重点も変わります。
- 自動生成部分は、毎回ゼロから仕様確認する対象ではなく、既知の生成規則に基づく部分として扱いやすい
- その代わり、案件固有ロジック、UI、権限制御、外部接続、例外時の業務判断など手動実装部分に重点を置く必要がある
- 単体テストについては、自動生成部分を原則省略候補としつつ、最終的な採否は案件ごとの品質方針で決める
特に管理者としては、「何をテストしなくてよいか」よりも、「どこにテスト資源を集中させるか」を明確にするほうが重要です。
また、品質保証は機能要件だけで閉じません。非機能要件への対応方針 で整理している通り、Nijoが強いのはデータ完全性、更新時の整合性、保守しやすい構造、ログやマイグレーションの土台です。一方で、認証認可、可用性、監視運用、災害対策、性能保証のような論点は、案件側の基盤設計や個別実装と組み合わせて担保する必要があります。
したがって、品質保証計画では次のように分けて考えるのが現実的です。
- Nijoの標準構成を前提に確認する項目: スキーマ変更が型定義、DBスキーマ、定型CRUDに正しく反映されること
- 案件側で重点的に検証する項目: UIの業務適合性、権限制御、外部連携、運用監視、性能、セキュリティ統制
- 両者をまたいで確認する項目: ログ設計、マイグレーション手順、障害時の復旧手順、変更時のレビューとリリース運用
この切り分けが曖昧だと、自動生成で既に揃っている部分に過剰な確認コストをかける一方で、非機能要件として個別に詰めるべき論点が抜けやすくなります。
自動生成されるコードの基本方針
生成されるのは、モダンな技術スタックで構成された「普通の」ソースコードです。 ブラックボックスなランタイムライブラリへの依存は最小限にすることを方針としています。
また、運用にあたり Nijo の知識がない人が後を引き継ぐタイミングが訪れることを考慮し、いつでもこのフレームワークを捨てることができるように注意しています。具体的には、生成されるコードは可読性を重視し、あくまで愚直にシンプルな処理とすることに主眼をおいています。これにより、将来的に発生しうるリスクに以下のような手段を採ることが可能になります。
- Nijo が生成するコードが原因であるバグが発生した場合に、緊急対応として該当箇所を手修正することで対応する。
- 運用が長引きNijoの知識を持つ担当者がいなくなり、通常のJavaScriptやC#の知識を持つ人しか集まらなくなったとき、自動生成機能を捨て、以降は全て手修正で運用していくと決める。(ただし、あくまでこれは最終手段であり、基本的にはNijoを使い続けた方が開発生産性の恩恵を受けやすい点には注意してください。)
影響調査・変更管理
Nijoを使う場合、モデル変更は生成コードの再生成とセットで管理する必要があります。
- モデル変更は、関連するコードに広く影響しうる
- ただし、生成コードには強い型定義が付くため、影響がある範囲は再生成時のコンパイルエラーとして表面化しやすい
- そのため、変更影響の一次確認は、再生成後の静的な検出を前提に進める運用と相性が良い
たとえば、以下の画像では、左側のペインでデータ項目名が「仕入単価_税抜」から「仕入単価_税込み」に変更されています。この状態でNijoのソースコード自動生成をかけなおすと、右側や下側のペインに出ているように、変更前の名前を前提としていた実装箇所がコンパイルエラーとして現れます。
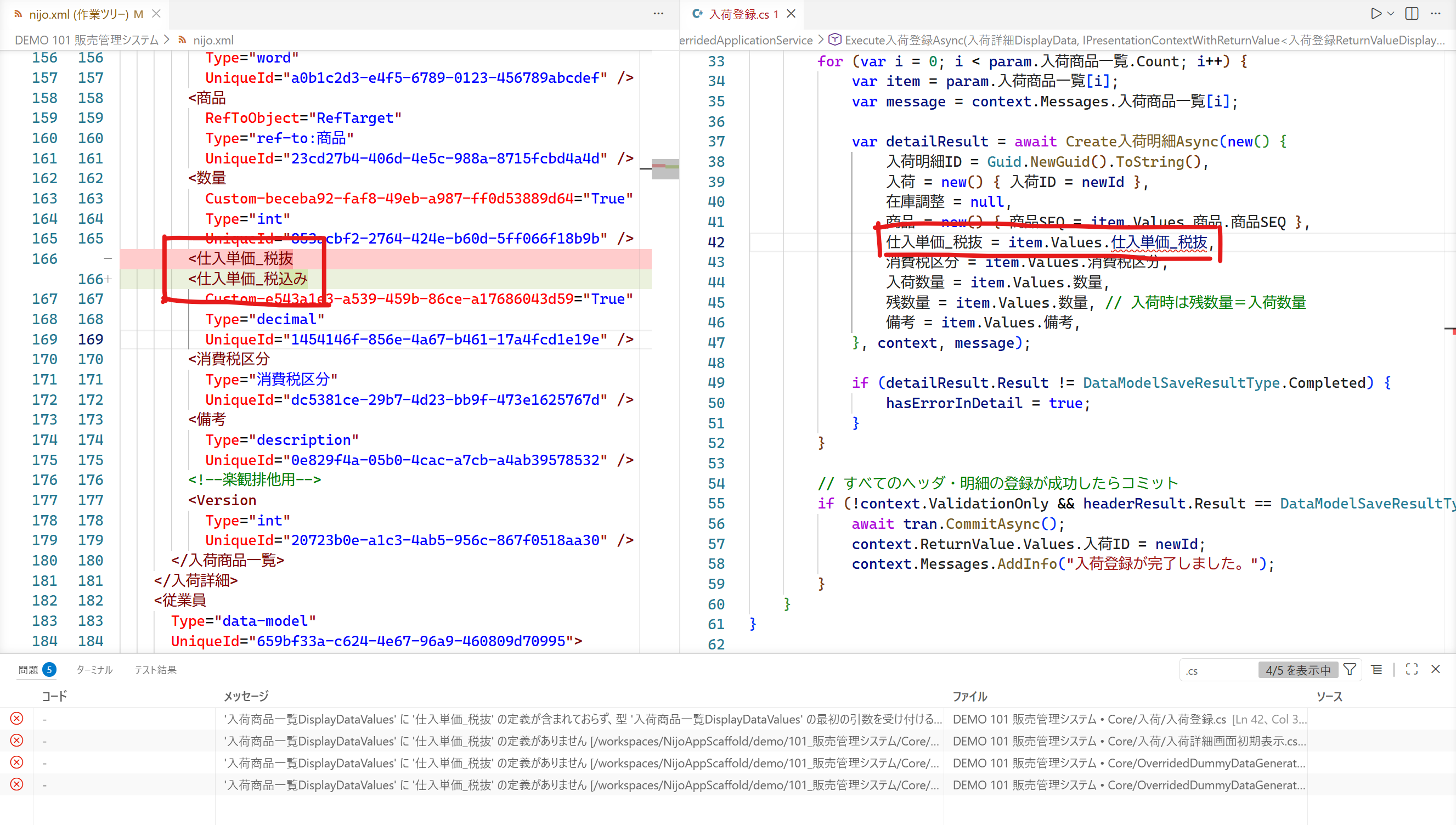
この挙動が意味するのは、変更の影響範囲を人手で全面的に洗い出さなくても、少なくとも型に現れる破綻は再生成とビルドで機械的に炙り出せるということです。管理者向けには、ここを変更管理プロセスに組み込むのが重要です。
- まずモデルを変更する
- 生成をかけなおす
- ビルドして、旧定義に依存していた実装をコンパイルエラーとして洗い出す
- 洗い出された箇所を修正し、レビュー対象を確定する
管理者向けには、変更管理の単位を「ソースファイル単位」ではなく、「モデル変更と再生成のセット」として扱うことを推奨します。 これにより、仕様変更時のレビュー観点を揃えやすくなります。